
For SEO specialists, content writers, PPC experts, and other digital marketers, constant updates are the key to keeping their sites up to date and boosting their SEO rankings.
However, most sites have hundreds or thousands of pages, which can be a challenge for teams that manually push updates to search engines. If you regularly update the content, how can you ensure that these improvements affect your SEO rankings?.
In this situation, the list of web crawlers is handy. A web crawler bot scrapes your sitemap for new updates and indexes the content in search engines.
In this blog post, we’ll discuss the list of web crawlers users must know.
What Do You Know About Web Crawlers?

As a netizen, you can assume web robots, web crawlers, or web spiders as computer programs that methodically browse the internet to obtain data and helpful information from websites.
Regarding the process, they start by analyzing a single web page, then follow links to identify and index other web pages. Thus, search engines locate and index content from various websites, making it searchable.
For instance, Googlebot is a notable web crawler that search engines use to crawl the web and build an index of web content.
How Do Web Crawlers Work?
Web crawlers usually work in the following way:
- They start their process by going through a list of web addresses.
- They scrutinize each web page’s code.
- They explore links on the page and add them to their list.
- They perform the same process for new pages they identify.
Once crawlers visit pages, they collect a wealth of information, including images, text, and other data related to the page. Search engines like Yahoo Search, Google, and others benefit from this collected information to help netizens find what they are looking for.
Key Types of Web Crawlers
There are different types of web crawlers, including:
- Search Engine Crawlers: These crawlers help create huge indexes of the web to leverage search results, such as Googlebot, DuckDuckBot, Bingbot, and Baidu Spider.
- AI & Training Crawlers: AI and training crawlers comprise specific bots, such as GPTBot (OpenAI) and ClaudeBot (Anthropic), which help store content for training large language models.
- Focused/Topical Crawlers: These crawlers search for specific types of information, such as price-comparison bots (e.g., Priceva) or academic crawlers, prioritizing depth within a niche over breadth across the whole web.
- Incremental/Revisit Crawlers: These crawlers periodically revisit websites to detect updates, new content, or changes, guaranteeing index freshness.
- Social Media/Bot Crawlers: Platforms, including Facebook (Facebook External Hit) and X, use social media/bot crawlers to index shared links and preview content.
- Site Audit/SEO Crawlers: Tools like Screaming Frog, AhrefsBot, and SemrushBot help examine websites for technical SEO issues, broken links, and site structure.
- Distributed/Parallel Crawlers: These crawlers improve speed and coverage by running multiple machines or processes simultaneously.
Leading Search Engine Crawlers Users Should Know
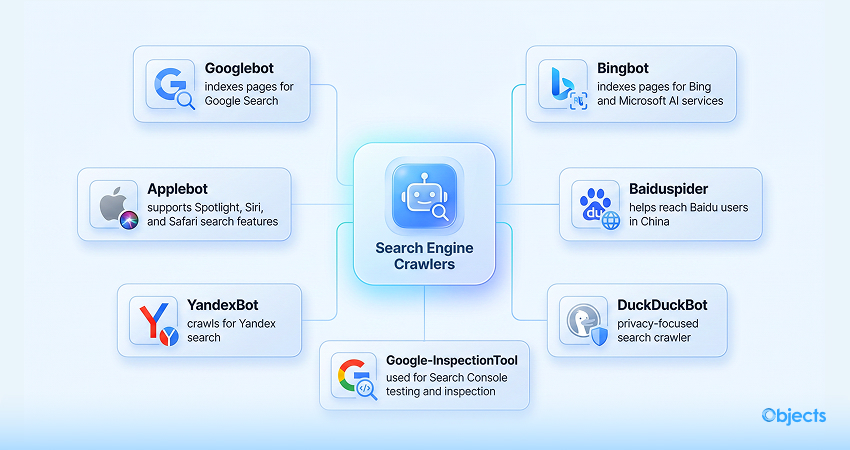
Frankly speaking, top web crawlers are crucial, as they adhere to key crawling rules and help site managers or owners index their sites for existing and prospective visitors worldwide. Some of the top web crawlers include:
- Googlebot: A famous web crawler developed by Google. This is one of the best web crawlers, offering many variants such as Googlebot-Desktop, Googlebot-Image, Googlebot Smartphone (Mobile-First), Googlebot News, Googlebot Video, and more. This web bot crawler analyzes pages and updates the index as well. Moreover, it enables the content to be shown in Google Search.
- Bingbot: Similar to Googlebot in terms of operation, Microsoft’s Bingbot helps index pages for Bing. Furthermore, the web crawler supports Microsoft’s AI-driven services, such as Bing Shopping AI, Copilot in Bing & Edge, Generative AI Search Results, Multimodal/Visual Search, and more.
- Applebot: Apple is the mastermind behind Applebot. The popular web bot crawls the web to gather and store content for core Apple services, including Spotlight and Siri. It follows the robots.txt rules and adheres to Apple’s privacy standards. Once it crawls publicly available information on the internet, search features like Spotlight, Safari, and Siri are improved to a certain extent.
- Baiduspider: Baidu Spider, as the name suggests, is the product of the Baidu search engine, one of the notable bots in China. If you prefer to attract an audience, activate the Baidu Spider to crawl your website and reach them.
- YandexBot: This bot is owned by Yandex (Russia). YandexBot adheres to robots.txt rules and is associated with the massive crawler community.
- DuckDuckBot: This bot is a brainchild of the DuckDuckGo search engine. Web admins can benefit from the DuckDuckBot API to check whether DuckDuckBot has crawled their website. Once it crawls, the DuckDuckBot API database gets updated with recent IP addresses and user agents. Thus, web admins can smartly detect impostors or malicious bots attempting to impersonate DuckDuckBot.
- Google-InspectionTool: It is one of the specialized web crawlers that search testing tools, including the Rich Result Test and URL inspection, use in Search Console. Aside from the user agent and user agent token, it behaves like Googlebot.
AI and Platform-Specific Crawlers
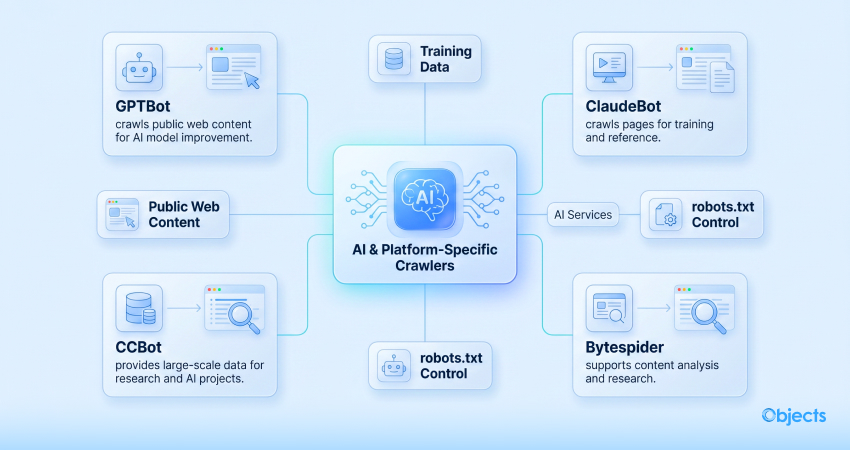
The evolution of artificial intelligence has enabled the development and expansion of new and existing crawlers that store web content to train language models or provide AI-based services. These bots are still new to the market but are more advanced than conventional search engine crawlers.
- GPTBot (OpenAI): This bot helps crawl and index public web content to enhance the productivity of AI models like ChatGPT. It gained user acceptance in 2023. Interestingly, users can block this leading web crawler using a robots.txt file.
- ClaudeBot (Anthropic): Another AI chatbot that crawls pages for training and reference.
- CCBot (Common Crawl): This non-commercial crawler offers data for search engine projects, AI research, and large datasets.
- Bytespider (ByteDance): TikTok developed this web crawler. Through Bytespider (ByteDance), users can perform critical tasks such as content analysis and research.
Other Notable Web Bots (SEO Tools, Scrapers, Aggregators)
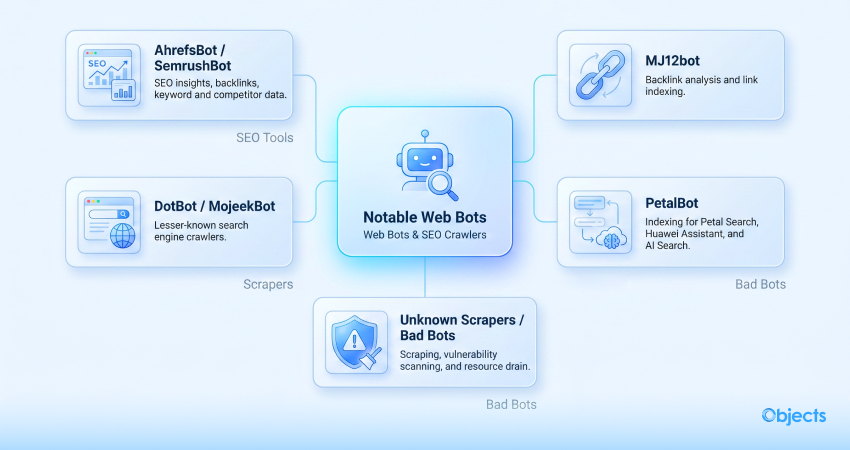
These bots are included in the web crawler list because they provide users with SEO insights or analytics. However, managing them is relatively challenging because some are resource-intensive.
- AhrefsBot and SemrushBot: These are used by SEO professionals to investigate backlinks, competitor data, and keyword rankings. They are helpful, but can result in a high crawl load.
- MJ12bot (Majestic): A renowned crawler that professionals and other users use for backlink analysis and link indexing purposes.
- DotBot and MojeekBot: These bots are suited to lesser-known or trivial search engines.
- PetalBot (Huawei): PetalBot is a useful bot powered by the Petal search engine. This bot crawler helps access desktop and mobile websites, builds an index database, enables users to search your site’s content in the Petal search engine, and delivers content recommendations in the Huawei Assistant and AI Search services.
- Unknown Scrapers and Bad Bots: Unlike well-known bots that value users’ trust and privacy, some bots don’t work on the same lines. They seem legal, but try to scrape users and drain them, scanning for vulnerabilities and depleting their resources.
SEO Benefits of Trusted Web Crawlers

Trusted or reliable web crawlers (e.g., Googlebot, Bingbot) help enhance SEO by identifying, rendering, and indexing content, thereby affecting visibility and ranking.
Key benefits include accelerated indexing of new content, recognition of technical issues like broken links or meta errors, optimization of crawl budget, and a fast, structured user experience that search engines prefer.
Different SEO benefits of trusted web crawlers are:
- Improved Indexing and Visibility: Crawlers detect, analyze, and catalog your site’s structure, keywords, and links, enabling search engines to index it and enhancing its presence in search results.
- Faster Content Discovery: When users publish new blog posts or update products, legitimate crawlers revisit your site to refresh search results, assuring your content remains up to date and relevant.
- Technical Audit Tool: Crawlers help users identify technical SEO issues such as duplicate content, broken links, and missing metadata, as well as crawl errors, ensuring ongoing health maintenance.
- On-Page Optimization: Crawlers provide valuable insights to optimize meta tags, headings, and keyword placement, helping avoid cannibalization or keyword stuffing. As a result, users can conform to search engine best practices.
- Enhanced User Experience (UX): When users inspect speed and structure, crawlers help them identify issues that can degrade the user experience, thereby indirectly enhancing rankings.
- Optimized Crawl Budget: Allowing reputable bots to crawl ensures they prioritize important pages, helping search engines understand your site hierarchy more efficiently.
How to Block Harmful Web Crawlers?
Using the web crawlers list, you can easily identify legitimate crawlers and unreliable ones. If you want to block dangerous web crawlers, you must analyze your web crawler list and explain each user agent along with its full agent string. Remember, the full agent string is coupled with each bot crawler and its IP address.
In short, each bot crawler has a unique user agent and IP address that help you identify whether the bot is trustworthy. You can recognize the bot by matching the user agent and IP address using a DNS lookup or IP match.
If the result doesn’t sound good, you need to block such a bot as it looks legitimate in the first place. You can change permissions using the robots.txt site tag to block the illegal bot.
How Can You Explain Web Crawler Bots?
The phrase “web crawler bots” is seldom used by users. If any user uses this term online, it means they discuss web crawlers or crawler bots. You can refer to web crawlers as “web crawler bots,” “bots,” “crawlers,” or “spiders” to describe the automated software that browses the internet to collect data and help search engines index web content.
How Can You Define the Bots Crawlers List?
The phrase “Bots Crawlers List” refers to software programs that access, download, and/or index content across the Internet. They help search engines understand what every webpage is about. Doing so will help them retrieve and show information when needed.
Wrapping Up
We expect you liked our blog post explaining the web crawlers list in detail. Web crawlers are crucial for marketers and search engines in many ways, and it’s important for marketers to realize their significance.
Ensuring the right crawlers crawl your site is critical to your business’s growth and success. A web crawler list helps you know which ones to remember and be mindful of them when you see them in your site log.
By keeping an eye on suggestions from commercial crawlers and optimizing your website’s speed and content, you make it easier for crawlers to analyze your website and index the appropriate content for search engines and users seeking it.
FAQs
What is web crawling?
Web crawling, also known as spidering, is an automated process that uses bots to analyze the internet, find, read, and index web content. Search engines benefit from web crawling to map and examine the web. Crawlers follow links from page to page, saving information to offer relevant, accurate search results.
Is Google a webcrawler?
Google uses a web crawler, Googlebot, to find, crawl, and index web pages across the internet. Googlebot works like automated software that systematically browses websites by following links from one page to another, gathering information about each page it visits.
Why should we care about which bots visit our sites?
Monitoring bot activity helps reduce server load. Additionally, site managers can fix SEO issues and leverage content strategies.
Are all web crawlers safe?
In general, reputable web crawlers are safe. However, you should be aware of malicious or unknown bot crawlers, as they can harm your site’s growth and reputation by causing spikes in traffic.
How do crawlers affect search engine rankings?
Crawlers index your content, making your pages more structured and accessible, ultimately improving your site’s visibility in search engines.


